It is strange to hear people talk about discourse grammar as though it is something altogether removed from discourse analysis based on the misconception that it doesn’t move “above the sentence level.” After all, if discourse analysis is really about discussing higher-level features and structures, how can what I do possibly qualify? This sounds like a reasonable criticism at face value, but it overlooks the reality of how many discourse devices actually operate. The sentiment seems to presuppose that there is a class of discourse devices that only operate above the sentence level that I am apparently ignoring, but how many can you name that only operate above the sentence?
Discourse analysis—at least the cognitively-based models like Walter Kintsch’s on reading comprehension—recognizes that understanding the function of the lower-level features is key to understanding their role at the higher-levels. Why? Because there are precious few “discourse-level only” features. Instead the vast majority play double duty, influencing and shaping our comprehension of the text at multiple levels.
Language has been studied and analyzed for centuries. Philosophers, linguists, logicians, and others have accumulated a rich store of knowledge about language. What has emerged, however, is not a uniform, generally accepted theory but a rich picture full of salient details, brilliant insights, ambiguities, and contradictions. Most of this work has focused on analyzing language as an object, rather than on the process of language comprehension or production. The importance of the actual process of language comprehension has not gone unrecognized, for instance, by literary scholars who have understood very well the role that the process of reception plays in the appreciation of a literary work, yet the tools for explicit modeling of comprehension processes have not been available until quite recently.1
Problem of Linearization
The features of discourse grammar on which I have focused play a key role in shaping our cognitive processing of the larger discourse. To begin with, we don’t read texts in massive chunks; we read them one word at a time. Even if we were to skip ahead or “speed read” we are still only reading one word at a time. Nevertheless, somewhere along the line in our comprehension of texts, we convert the single words into more abstract mental representations of the text. The lower-level features are, in reality, also the author’s instructions for organizing and structuring the higher-level representation of the text as a whole. In communication, the writer/speaker faces a significant constraint, referred to as the problem of linearization.

The Problem of Linearization
Linearization describes the fact that we can only produce one word at a time, one sentence at a time; conversely the reader/hearer can only take in one word at a time, one sentence at a time.2 If the reader does not properly comprehend how the individual words, phrases and clauses relate to one another, miscommunication will inevitably result. Consider the difference that a simple comma makes in the title of Lynne Truss’ bestselling book on English punctuation.3
a) Eats, shoots and leaves.
b) Eats shoots and leaves.
The presence or absence of the comma here is the difference between discharging a weapon after a meal versus a comment about the diet of an herbivore.

The presence of the comma in a) provides instructions intended to overcome the linearization problem. The comma in a) constrains the reader to view “shoots” and “leaves” as verbal actions, whereas its omission in b) constrains the same words to be read as direct objects describing “what is eaten.” You see, lower-level features are the keystone to understanding higher-level structures. Failures at the bottom are magnified the higher up one moves in their analysis.
Bottom-Up or Top-Down?
The problem of linearization has important ramifications for how one analyzes discourse. There has been an ongoing debate in biblical studies about which approach to DA is superior: Should it move from the top-down, or from the bottom up? Are they actually mutually exclusive?
Kintsch’s research from the past several decades has demonstrated that our reading of written texts is really a combination of both. His finding are based on empirical research into human cognition and language processing of written texts—not an abstract model of what might be happening when we read or listen to a discourse.
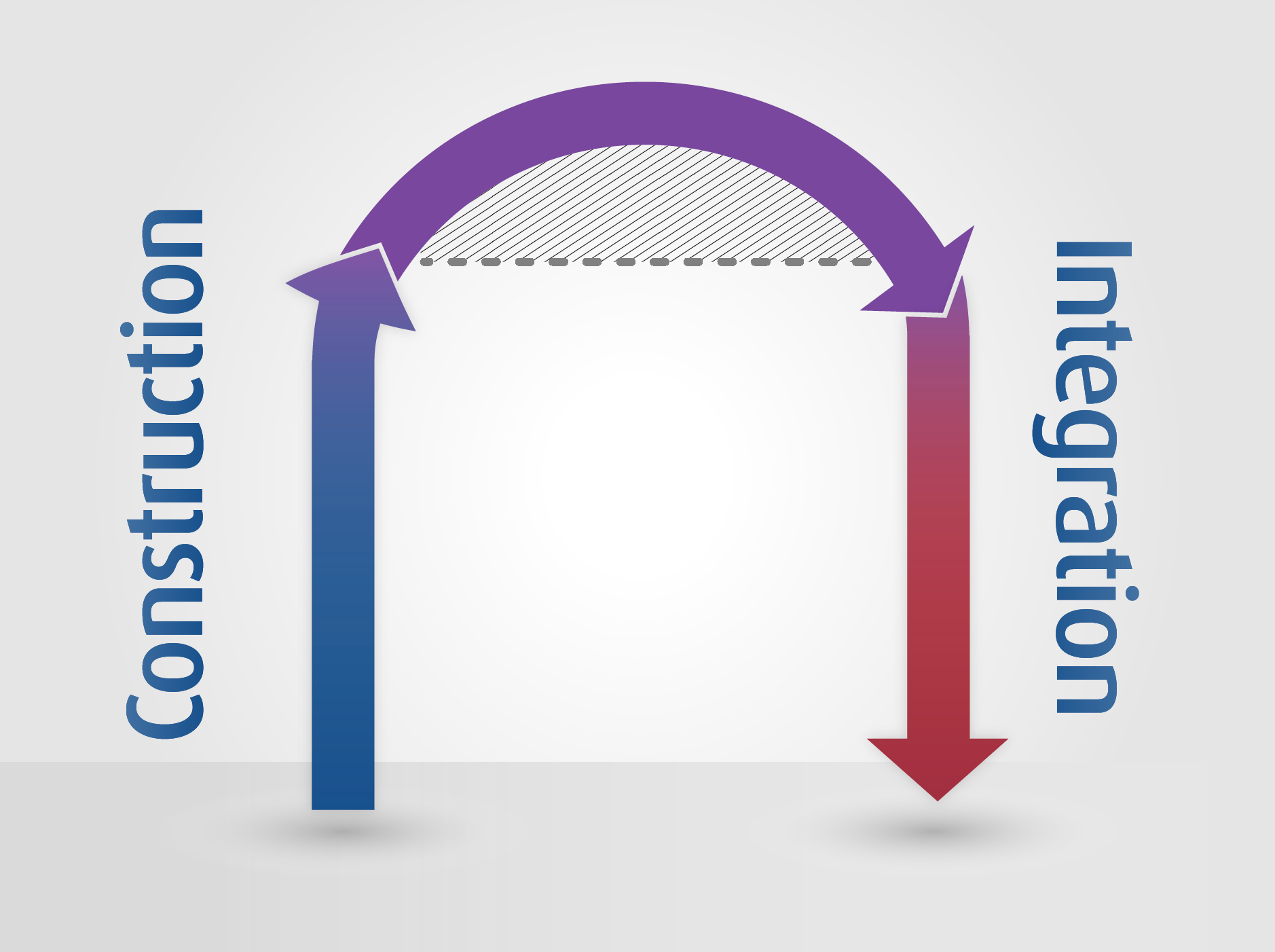
Kintsch has found that our reading of texts involves an iterative and almost simultaneous bottom-up and top-down processing, which he refers to respectively as “construction” and “integration.” As we read, we necessarily process language linearly—one chunk at at time. This is the bottom-up phase which Kintsch calls construction. We construct a mental representation of the text itself as we read, as modeled in the linearization illustration above. But this is not all that is happening.
As the bottom-up construction occurs, there is also a top-down process occurring referred to as integration. The newly forming mental representation of a text doesn’t exist in an isolated silo of our brain. Instead Kintsch has demonstrated that we integrate the new one into our existing, larger mental representation. This integration is not simply with the earlier portion of what we’ve read or even other books we’ve read, but with the sum of our knowledge about the world and how it operates based on our prior learning and experiences. This is a simplification, but gives you an idea of the importance of factoring cognitive processing into a model of discourse analysis.
Kintsch’s description of the integration-phase of language processing has great explanatory power, helping us understand how it is possible for two people to read the same text and come up with quite different conclusions about it. Differences in background knowledge, goals, and presuppositions all play a role in how we process a text. We don’t just read a text, we also integrate it with what we already know. This also explains why some of you who read this blog post will cheer it while others reject it or find it boring. Our own mental representation of the world—and presuppositions about DA—play a huge role in how we process new texts or communication.
Analyzing Higher-Levels of Discourse
Now lets return to the original question about my focus on sentence-level features versus tackling higher-level analysis. The linearization problem gives us a clue about the significance of lower-level features to higher-level shaping of the discourse. The ugly little truth is this: The higher up one goes in the analysis of discourse, the fewer explicit and unambiguous markers there are to guide the analyst. Instead, higher-level analysis is driven by our mental representation of the discourse, which in turn goes back to things like chunking into developments, information structure, forward-pointing devices, the thematic prioritization of information, and our existing mental representation of the world. These lower-level features impact the higher level as they are integrated into our larger mental representation of the discourse. In this sense, talking about levels of discourse is largely a theoretical abstraction, not necessarily modeling how we actually process texts.
Focusing on the the lower-level features pays dividends as one moves to the higher-levels. Why? Many features that operate at the lower-levels also impact the higher-levels, as alluded to above. In fact, there are very few linguistic features that exclusively operate at higher-levels. Most that come to mind are actually type-setting or orthographic conventions, like paragraphing and titling. These are largely modern conventions.
Lower-level features are able accomplish higher-level functions as they are found clustered together with other features. For example, inferential conjunctions like ουν are rightly viewed as having a higher-level function, but they nevertheless still simply conjoin two clauses. Judgements about joining higher-level units are made by considering the co-occurence with other “boundary features” like those described by Levinsohn in Discourse Features.
 So in terms of methodology, Levinsohn and I may begin with sentence-level features, but this is not where things end. The lower-level analysis necessarily serves as a foundation. Think Lombardi; the game is won or lost based on how well we have mastered the fundamentals. If there are problems there, they tend to compound as one moves up in their analysis.
So in terms of methodology, Levinsohn and I may begin with sentence-level features, but this is not where things end. The lower-level analysis necessarily serves as a foundation. Think Lombardi; the game is won or lost based on how well we have mastered the fundamentals. If there are problems there, they tend to compound as one moves up in their analysis.
Focusing on lower-level analysis also plays a “quality assurance” role in higher-level analysis of texts. It allows us to double check our work using a top-down reading to ensure we are able to reconcile all lower-level analyses with our higher-level claims. If we can’t, then we need to go back and figure out where we went wrong. Any who have done DA with me at SBTS, DTS, WEST, or Wycliffe Hall-Oxford can attest to this. Just like Bugs Bunny, I can miss that important turn at Albuquerque and need to reconsider lower-level decisions to better account for higher-level phenomenon.
In contrast, those focusing solely on “discourse-level” features are not troubled by implications from discourse grammar. The biblical writer’s lower-level choices that contradict the analyst’s higher-level claims can only serve as a corrective if the analyst has attended to them. Otherwise ignorance is bliss, so to speak.
This explains my preoccupation with “sentence-level” features, like connectives, highlighting, and structuring devices. Call me silly, but it would seem that if one has properly understood how a device operates in simplex context at the lower-levels, then one will be in a much better position to adequately describe its much more complex interaction with other features at the higher-levels of discourse processing, i.e. the integration stage. Again, I am not really sure we can discretely separate higher-level from lower if the same devices operate at both.
Practical Payoff of Discourse Grammar for DA
There is a time for doing DA, but we should not rush on to higher-level analysis at the expense of attention to lower-level details. Why? If the lower-level exegesis is flawed, think about the implications for the higher-level conclusions drawn. I have opted to major on the lower-level in order to avoid preventable mistakes at higher levels.
Those who complain that discourse grammar only considers sentence-level features must have very different presuppositions about DA and how discourse features actually work. Because I am not postulating about broader themes of a book or “zones of turbulence,” I therefore must not be doing DA. But our methodology must account for the reality that most linguistic features contribute at multiple levels of the discourse. In other words, zones of turbulence are best understood as a clustering of discrete, describable, sentence-level discourse features that function in concert to accomplish a higher-level function. Making assertions about higher-level features is one thing; being able to describe how the lower-level features contribute to make the higher-level result is quite another. If there really is a zone of turbulence, then your case will be strengthened by demonstrating the contribution of each component.
There are indeed different levels of analysis, but failures in the lower levels tend to be magnified at the higher-levels. Attention to the lower levels provides a safeguard and corrective to the higher-level analysis.
For those who criticize me for focusing on sentence-level phenomenon, the discussion and diagrams above are a preview of a larger project I will be undertaking in 2015 on moving from discourse grammar to discourse analysis. Discourse Grammar of the GNT was intended to serve as a foundation for later work, not as a manual for analyzing discourse. The newly shipped High Definition Commentary: Romans offers a simplified example of my approach to DA, demonstrating its practical payoff for the pastor or teacher.
- Walter Kintsch, Comprehension: A Paradigm for Cognition (Cambridge; New York: Cambridge University Press, 1998), 93. ↩
- Gillian Brown and George Yule, Discourse Analysis, Cambridge Textbooks in Linguistics (Cambridge; New York: Cambridge University Press, 1983), 125. ↩
- Lynne Truss, Eats, Shoots, and Leaves: The Zero Tolerance Approach to Punctuation (New York and London: Penguin, 2003). ↩
Steve, thanks very much for this excellent post. More and more in my own research, I am realizing just how true it is that top-down and bottom-up analyses are necessarily related to and inform each other. Your post very helpfully explains why this is!
Your post reminded me of a part of Michael Hoey’s book on discourse analysis (Textual Interaction, Routledge). In it, he deals with both top-down and bottom-up (though, top-down is focused on more), seamlessly moving between the two. At one point he writes:
“Discourse decisions have grammatical implications, and of course conversely every grammatical decision has potential discourse implications…. Patterns of text organisation are grounded in the detail of the text. Discourse description that does not engage with this detail is not truly linguistics – it may be literary, semiotic or rhetorical and have a value in such terms, but the linguistic description of text/discourse, as well as developing its own categories, must also engage with the categories of other levels of linguistic description.” (p. 61)
[…] dialogues. However, once we consider the structure of the discourse above the sentence level (in a discourse analysis) we can see beyond the twin mistakes made in the stereotypical liberal/conservative, […]
[…] However, once we consider the structure of the discourse from above the sentence level (in a discourse analysis) we can see beyond the twin mistakes made in the stereotypical liberal/conservative, […]
Splendid post, Steve.